はじめに、私がなぜFirefly Campへ参加したのか?

引用元:動画制作をレベルアップする Firefly 生成 AI 機能の活用術!| Firefly Camp
つい先ほど Adobe Firefly Camp(オンライン)に参加しました。参加の目的は「商用利用におけるAdobe Fireflyの著作権保護の考え方を、公式のコメントで確認したい。」その1点でした。
私のケースでは2023年から徐々に、クライアントに納品する成果物に「生成AIの成果物が混ざる案件」が増え続けています。それ自体は時代の流れとして自然なことですが、AI生成成物の著作権・肖像権の管理が日常業務として重くのしかかっています。
生成AIに関しては日本国内の法整備はまだ曖昧な部分が多く、「商用利用してよいのか?」「訴訟等のリスクをどう管理するか?」という問いに対して、明確な指針がないまま現場は動いています。残念ながらそれが現実です。
ですが、そのような状況だからこそ、クリエイティブツールのトップランナーである「AdobeがAIの著作権についてどう考えているのか?」を直接確認したかったのが参加目的でした。
Adobe Fireflyが示した「4つの著作権対策|商用利用のための安全策」
セッションが始まると期待通り、Adobe FireFlyの安全性についてのインフォグラフィック・アニメーションが流れました。Adobe After Effectsで制作された視線誘導に優れた作りで、その内容は以下の4点に整理されていました。なお、その動画はAdobeのYouTubeチャンネルで視聴できます。
1. 著作者の許可を取得している
類似画像が生成されても「事前に著作者の許可を得ていれば著作権侵害には問われない。」という正論です。
2. 著作物を無断で学習していない
著作権侵害の成立要件は「無許可で模倣すること」ですが、「Adobeがコントロールできるデータのみを学習させている。」というアプローチです。
3. 学習データを公開している(透明性の担保)
私にとっては、ここが今回のセッションのコアでした。Adobe Fireflyが学習しているデータは、次の2種類に限定されるそうです。
✏️ 3-2. Adobe Stockコントリビューターから許諾を得たデータ:権利者の同意を取得済みのため、類似コンテンツが生成されても問題なし
つまり「FireFlyに学習させていないものは、似ていても問題は生じない」という論理です。
4. 人間によるレビュー体制の強化
上記の学習データ選定プロセスにおいて、専任スタッフ(人間)がアセットのチェックを行っており、著作物やAI生成物が学習データに混入しないよう管理されているとのことでした。安全性確保のため、レビュースタッフは “3倍” に増員し、監視体制も強化されているそうです。
それでも残った2つの疑問
Adobe側の説明は論理的で、公式資料としての完成度も高いものでした。しかし聞き終えた後、私には “2つの疑問”が残りました。
疑問①:人間のチェックだけで、学習データの純粋性は担保できるのか?
「専任担当者が適切と判断したもの以外は学習させていない」という説明には、一定の信頼感があります。ただ、人間のレビューのみで、著作物の混入をゼロにすると断言できるのでしょうか?
現代の著作物の量と多様性を考えると、人間の目だけでの判定には限界があります。むしろ、AIによる一次スクリーニングと人間による最終判断という二重監視体制こそが、透明性をより確かなものにするのではないかと感じました。この点は建設的な提案として、Adobeには今後の検討を期待したいところです。
疑問②:パートナーモデルの著作権は「透明性」が担保されているのか?(これが私からの質問です。)
こちらが今回のキャンプに参加した目的(知りたかったこと)でしたが、数週間前から事前質問として提出していたにもかかわらず、キャンプ内では取り上げてくれませんでした。続けます。
核心の問い:パートナーモデルという「グレーゾーン」
Adobe Fireflyには、Adobe独自の生成AIモデル(Firefly Image 3〜5など)のほかに、他社が開発したパートナーモデルが多数統合されています。実際のUI(下図参照)では、以下のような画像生成モデルが選択可能です。
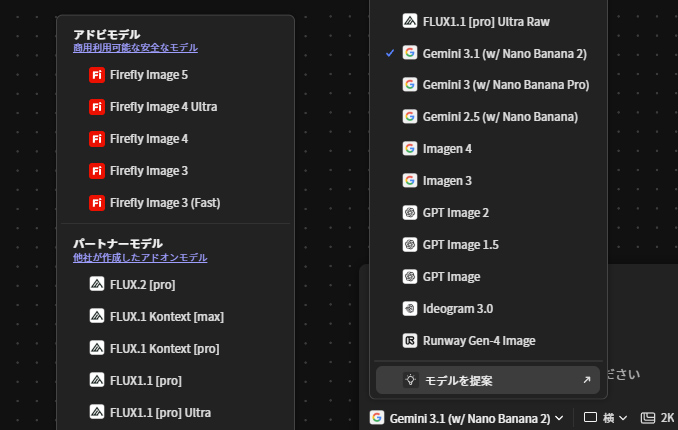
✏️ Geminiシリーズ / Imagen(Google)
✏️ GPT Imageシリーズ(OpenAI)
✏️ Ideogram / Runway
これらは「他社が作成したアドオンモデル」として明示されており、Adobeのプラットフォーム上から直接利用できます。
問題の本質について
Adobe独自モデルであれば、先述の4つの安全策はAdobeが責任を持って管理・保証できます。しかしパートナーモデルの学習データは、Adobeの審査を通過しているとは考えにくいです。
たとえばGoogleのGeminiモデルについて言えば、GoogleがAdobeのために学習データの内容を開示・検閲するとは現実的に考えられません。また、AdobeとGoogleの間に包括的な契約があったとしても、「Adobe製品のユーザーが著作権侵害で訴訟された場合にGoogleが補償する」または「Googleの莫大な学習データを、全てAdobeに公開して削除可能とする」といった条項が存在するとは、到底思えません。
つまり、ユーザーがパートナーモデルで生成したコンテンツについて、Adobeが謳う「学習データの透明性(上記の3-1、3-2)」は適用されない可能性が極めて高いでしょう。
答えのない問いが示すもの
私はこの質問を、キャンプの数週間前から事前質問として提出していました。そしてキャンプ当日のQ&Aでも手を挙げましたが、取り上げてもらえませんでした。
意地悪な見方をすれば、「答えにくい質問だったから回避された」と解釈することもできます。ただ、それが意図的なものかどうかは私には分かりません。可能性としては、Adobe社内でもパートナーモデルの著作権保証については、まだ公式見解が整理しきれていないのかもしれません。であるならば、なおさら「Adobe Fireflyは安全です。」と言い切るのは危険ではないでしょうか?
いずれにせよ、この点が曖昧なままでは、私が講師を担当するSTUDIO USでは「Adobe Fireflyを使った教材や制作フローを、受講生に提案できない。」という状態が続くでしょう。
【おすすめ記事】🔮AIを学べば儲かる?の罠について理解しよう!

まとめ:透明性の「外側」にある問題
とはいえ、Adobe Fireflyが掲げる著作権の透明性は、Adobe独自モデルの範囲内においては、業界の中でも「実に誠実な取り組み」と認識しています。学習データの開示、コントリビューターとの契約、人間によるレビュー体制——これらは他のAIサービスと比較しても、とても丁寧な対応です。
しかし、プラットフォームが多様なパートナーモデルを取り込んで拡張していく中で、「Fireflyのブランド=安全」という等式は成立できていない。とも思います。
これはAdobe固有の問題ではなく、複数のAIモデルを統合したプラットフォーム全般が直面している課題でもあります。だからこそ、業界をリードするAdobeには、パートナーモデルを含めた著作権保証の枠組みを、早期に公式見解として示してほしいと考えています。今後も公式回答を待ちながら、引き続きこのテーマを注視していきたいです。